

Kostengünstig & Cloud-unabhängig: Smart-Home-Sprachsteuerung mit Snips
Speaking machines can’t
They just howl around
Like the vultures and the crows
It’s so hard to say
It’s so hard to say
Something clever all the way
(Speaking Machines, We are Match)
Liebe Freunde – es wird euch kaum entgangen sein: Wir haben uns erst vor Kurzem mit der Sprachsteuerung im Smart-Home beschäftigt. Der erste Prototyp in diese Richtung war nicht sehr viel versprechend…
Wir geben allerdings nicht auf und verfolgen diese Spur mit dem nächsten DIY-Prototypen weiter. Die Schwiegermutter soll ja dadurch irgendwann Bauklötze staunen! Nun aber zur Sache:
HEY SNIPS! Erzähle uns über dich…
Grund-Aufbau
Die Hardware bleibt nach dem ersten Versuch unverändert:
- Respeaker Core V2
- Micro-SD-Karte (16 GB)
- Aktive Lautsprecher
- Laufende Edomi-Instanz
Software
Die Software-seitige Umsetzung hat folgende Grundzüge, benötigt werden zunächst:
- Respeaker Betriebssystem (Debian) als Basis und Schnittstelle zur Hardware
- snips.ai für die Sprachverarbeitung
- Edomi für Smart-Home-Aktionen
Snips.ai ist ein (derzeit kostenloser) Online-Service, der es mit relativ wenigen Eingaben erlaubt einen vollwertigen Sprach-Assistenten zu kreieren und ihn dann – und das ist die Krux – vollständig offline und autark, lokal zu betreiben! Mit wenigen Handgriffen lassen sich durch Definition einfacher Trainings-Satz-Formulierungen und Schlüssel-Begriffe die ersten Ergebnisse erzielen.
Die Idee der Sprach-Verarbeitung und -Steuerung ist immer-noch recht simpel gehalten – nehmen wir an, wir wollen die Beschattung im Raum/Haus auf etwa 80 % fahren:
- Wir aktivieren Snips mit einem (voreingestellten) Signalwort: “HEY, SNIPS!”
- In das Mikrofon gesprochene Sprache wird von der lokalen Snips-Instanz erkannt (STT = Speech-To-Text) [“Fahre die Beschattung im Bad auf 80 %!”]
- Ein Signal (JSON-String) über das ausgewertete Gesprochene wird von Snips über MQTT an Edomi übertragen [BESCHATTUNG-BAD-80 %]
- Edomi verarbeitet den stukturierten JSON-Payload und löst ggf. Aktionen aus [Jalousie-Aktor fährt die Beschattung auf 80 %]
- OPTIONAL: Snips empfängt eine Nachricht über MQTT von Edomi und gibt u. a. gesprochene Sprache aus (TTS = Text-To-Speech) [“Verstanden: Beschattung aktiviert!”]
Spracheingabe (STT) ➡ Snips Intent ➡ Edomi ➡ Snips Audioserver ➡ Sprachausgabe über Snips (TTS) und/oder (beliebige) Aktionen
Die Snips-Installation auf unserem Respeaker bringt alles Notwendige (inkl. eigenem MQTT-Broker) mit. Installiert wird dabei nach den Vorgaben der Snips-Väter/Mütter: https://docs.snips.ai/articles/other-platforms/respeaker-core-2.0.
Anschließend erstellen wir mit dem Online-Dienst (Snips Console) https://console.snips.ai unseren ersten Assistenten:
- Create Assistant ➡ “Edomi”
- Add an App, Create a new App ➡ “SetShutter”
- Create new Intent ➡ “SetShutterPositionIntent”
- Create new Slot ➡ “PositionValue”, Slot Type: snips/percentage
- Create new Slot ➡ “ShutterDesc”, Select: Create New Slot Type -> Gruppen/Synonyme anlegen
- Create new Slot ➡ “Location”, Select: Create New Slot Type -> Gruppen/Synonyme anlegen
- Mehrere Trainingssätze eingeben ➡ Doppelklick auf Schlüssel-Begriffe im Trainingssatz (z.B. Location “Bad”) -> Location-Slot zuordnen



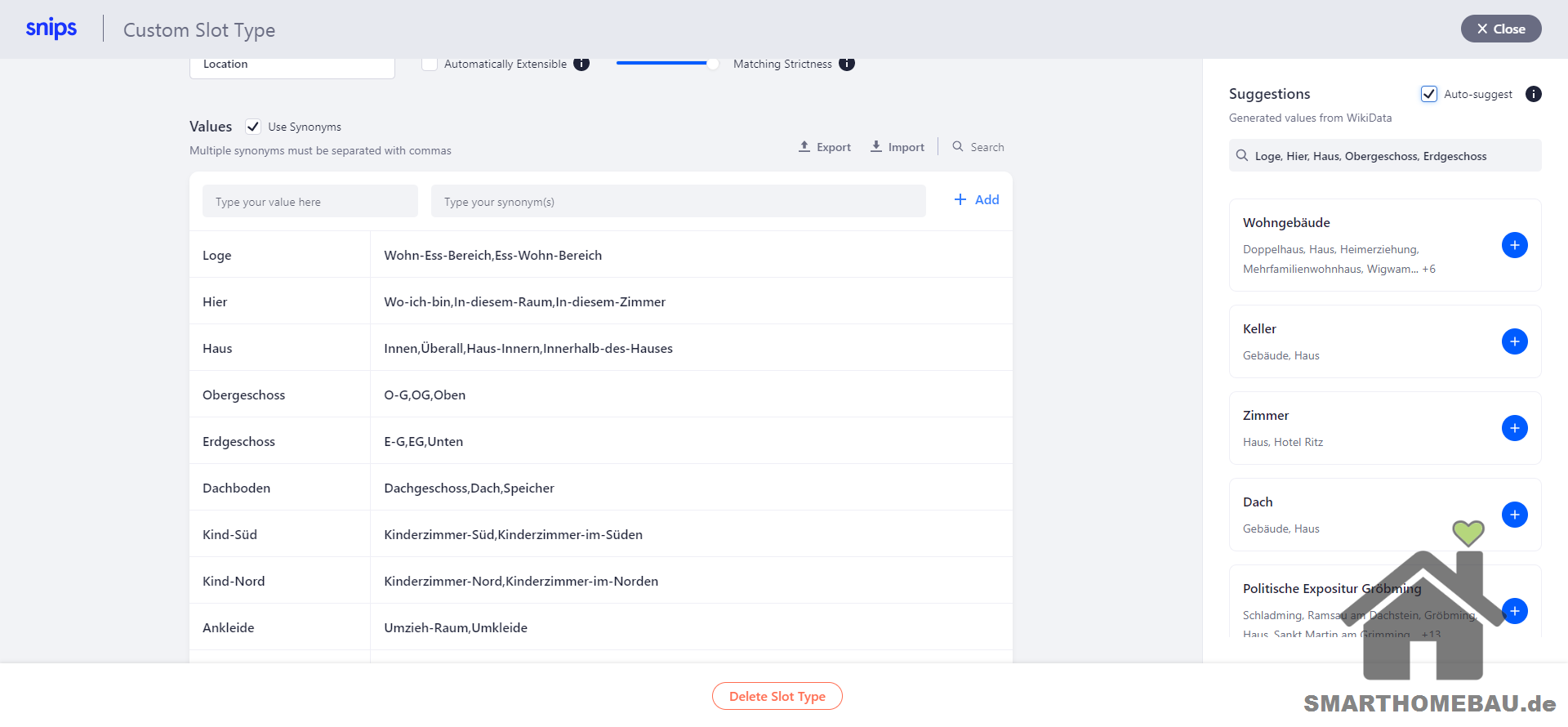
Snips’ Nomenklatur ist in wenigen Worten beschrieben: Ein “Assistant” fasst unter einer gemeinsamen Sprache (hier “German”) und einem Spracherkennungsdienst (ASR = Automatic Speech Recognition) mehrere “Apps” zusammen.
Eine App umfasst alle Elemente für eine bestimmtes Ziel des Nutzers; z. B. Beschattungs-Steuerung.
Die “Intents” einer App bilden so die Absichten eines Nutzers ab: Beschattung in eine Position (80 %) fahren oder Beschattungs-Richtung (auf/ab) steuern – um nur einige Beispiele zu nennen.
Der “Slot (Type)” eines Intents hilft bei der Unterscheidung bestimmter Schlüssel-Begriffe. Der Slot “Location” in unserem Beispiel hilft uns einen bestimmen Raum/Lokalität eindeutig zu bestimmen und anschließend anzusteuern. Die Synonyme innerhalb des Slots bestimmen hierbei die möglichen Ausprägungen (“Bad”, “Badezimmer”, “Master-Bad”, usw.). Slot Types können auch wiederverwendet werden und so App-übergreifend eingesetzt werden.

Ist der Assistent fertig definiert – kann er nun lokal heruntergeladen und installiert (deployed) werden – dies wird gemäß Anleitung wie folgt erreicht:
sudo apt-get install unzip (optional, falls unzip fehlt)
sudo rm -rf /usr/share/snips/assistant/
sudo unzip {assistant.zip} -d /usr/share/snips/ ({assistant.zip} = Name der Datei)
sudo systemctl restart 'snips-*'
Somit ist Snips lokal einsatzbereit und veröffentlicht ab sofort über seinen MQTT-Broker die Ergebnisse der eigenen Spracherkennung und -Interpretation.
Die Auswertung in Edomi ist trivial: Der MQTT-JSON-Payload wird zerpflückt und mit wenigen Logik-Bausteinen verarbeitet. Der entsprechende Snips-Intent wird hierbei über ein MQTT-LBS abboniert. Der JSON-Inhalt liefert alle erkannten Slots, in unserem Fall zum Beispiel:
Location: Bad
ShutterDesc: Rollladen
PositionValue: 80 %
Die (Rück-)Meldung an Snips zur Sprachausgabe wird ebenfalls über eine JSON-MQTT-Nachricht abgewickelt:


Und so kann es ablaufen:
Fazit
Pro:
Kostengünstig!
Schnelle Ergebnisse!
Vollständig offline bzw. autark!
Gute Erkennungs-Qualität!
Weitreichend konfigurierbar (TTS, Hotword, etc.)!
Empfangs-Gerät/Instanz nicht auf einen einzigen Raum beschränkt, jeder weitere Raum kann über einen sog. “Satellite” angebunden werden!
Contra:
Standard-TTS (picotts) ist zwar brauchbar, aber stark verbesserungswürdig…
Verarbeitungslogik muss mühsam für alle möglichen Gewerke/Lokationen usw. manuell aufgebaut werden.
Software teilweise zu stark allein auf den Raspberry Pi ausgerichtet
Abhängigkeit zum Online-Dienst (Console) bei der Assistent-Erstellung/Anpassung.
Das macht Lust auf mehr! Unser bescheidener Aufbau muss sich kaum hinter den teuren, kommerziellen Lösungen verstecken. Während die käuflich erwerbbaren Produkten nur auf wenige, starre, fest definierte Funktionen (Licht, Beschattung, Heizung, Szenen) beschränkt sind, sind uns mit der Bastel-Lösung kaum Grenzen gesetzt!
Weitere Ausbau-Schritte
Welche Schritte planen wir also als Nächstes?
Steuerung:
- Steuerung (gedimmtes) Licht (+ evtl. Lichtfarbe)
- Steuerung Beschattungs-Richtung (Ab/Auf/Stop)
- Steuerung Tür-Entriegelung
- Steuerung Automatiken (Status, Start/Stop)
Auskunft:
- Zeit/Datum (“Wie spät ist es? ➡ Es ist 17 Uhr 35.”)
- Wetter (“Wie ist das Wetter? ➡ Sonnenschein mit 25° C.”)
- Nachrichten (“Was gibt es Neues? ➡ Im Westen nichts Neues.”)
- Zugfahrplan, inkl. Verspätungs-Ansage (“Wann fährt der nächste Zug nach Buxtehude? ➡ Der nächste Zug nach Buxtehude geht um 12:45 Uhr, mit 7 Minuten Verspätung.”)
- Geo-Position (“Wo ist Walter? ➡ “Walter war vor 11 Minuten in Holzweg 47, 12345 Buxtehude.”
- Termine (“Nenne mir meine Termine heute! ➡ 12 Uhr 30: Zahnarzt!”)
- Abfall-Termine (“Wann wird der Bio-Abfall geholt? ➡ Der Bio-Abfall wird – in 7 Tagen – am Donnerstag, den 7. November abgeholt.”)
- etc.
Szenen:
- TV-Szene (Licht aus, Beschattung ab, Kodi an, usw.)
- Aufwachen-Szene (Rollladen auf, Licht gedimmt, gedämpfte Musik, usw.)
- etc.
Musik-Steuerung:
- Sonos
- Spotify
- etc.
Weitere Überlegungen (Zukunftsmusik):
Ein ansehnliches Gehäuse (inklusive Lautsprecher) für die Hardware wird gesucht.
Optische Rückmeldung bei der Verarbeitung über die eingebauten LEDs des Respeaker Core V2 wären ganz nett.
Satelliten-Setup für weitere Räume im Gebäude sollten eingerichtet werden.
Testen eines alternativen/angenehmeren TTS: Mycroft AI (mimic)scheint eine gute Option zu sein.
Nicht schlecht, oder! Dann baue es nach! Oder sprich uns auf’s Band… 🎤








































[…] nun obsolet. Ihr ahnt es vielleicht es schon, es geht um die Fortführung des Aufbaus für einen Sprachassistenten mit Snips. Wir haben nämlich ein ansehnliches praktisches Gehäuse für den Assistenten […]
[…] Sprachassistent […]